LLM의 새로운 최신 정보 학습 방법(Continual Learning, RAG)
배경
- LLM은 고정된 데이터에 대해서 학습된 모델이기 때문에 시간에 따라 변하는 새로운 지식을 학습하지 못하는 문제가 있다.
- 시간에 따라 변하는 지식을 질문했을 때, LLM은 Hallucination에 의한 부정확한 정보를 출력할 가능성이 매우 높아진다. (ex. 오늘의 서울 날씨 등)
- 또한, 예전에 학습된 모델일수록 Perplexity가 증가한다.
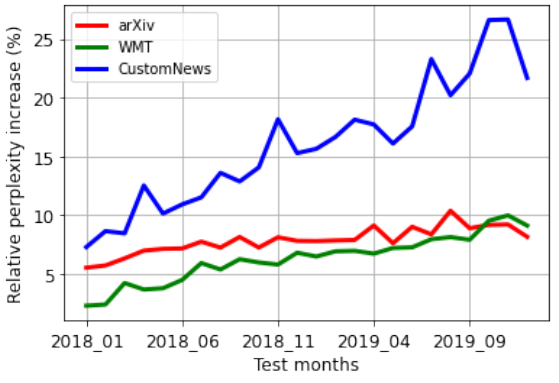
(출처: Lazaridou et al., "Mind the Gap: Assessing Temporal Generalization in Neural Language Models", NeurlIPS, 2021) - 위 그림에서 볼 수 있듯이 다양한 데이터셋에서 학습된 모델들이 공통적으로 시간이 지남에 따라 Perplexity가 증가하는 것을 볼 수 있다.
- 또한, 비교적 시간에 따라 변하는 정도가 큰 News가 Scientific text보다 크게 Perplexity가 증가한다.
문제 해결
단순히 새롭게 업데이트 된 데이터를 기존 학습된 LLM에 FineTuning 하는 방법
- Catastrophic forgetting 문제 발생
- 여러 테스크를 순차적으로 배울 경우, 앞선 테스크에서 학습한 정보를 잊어버리는 문제

(출처: Zhai et al., "Investigating the Catastrophic Forgetting in Multimodal Large Language Models", CPAL, 2024) - 위 그림에서 볼 수 있듯이 이전에 CIFAR10에서 미세조정된 LLM을 MNIST로 미세조정한 뒤에는 원래 맞추던 문제도 못맞추는 문제가 발생한다.
- 여러 테스크를 순차적으로 배울 경우, 앞선 테스크에서 학습한 정보를 잊어버리는 문제
Continual Learning
과거 정보를 까먹지 않으면서 LLM을 추가로 학습하는 방법
- 데이터 별
- 도메인 별
- 예시) 생명과학 -> 컴퓨터 과학 -> 재료 공학 -> 물리
- 시간 별
- 예시) 2017 -> 2019 -> 2021 -> 2023
- 도메인 별
- 방법론 별
- Regularization method
- 매개변수를 적게 바꾸는 방식
- 기존의 매개변수에서 크게 차이가 나지 않도록 규제
- 기존 매개변수와의 L2거리 최소화 등
- 대표적인 방법 : EWC, Rec-Adam
- Parameter expansion method
- 추가 매개변수를 학습하는 방식
- 원래 매개변수는 고정, 새로운 모듈을 추가해서 학습하는 방법
- 대표적인 방법: LoRA, K-Adapter, Prefix Tuning, Prompt tuning
- Rehearsal method
- 과거 학습 데이터를 같이 학습하는 방식
- 대표적인 방법: Mix-review, Deep generative reply (DGR)
- Regularization method
- 한계
- 매일 매일 변하는 지식은 계속 학습 시키기가 어려움
- 결국 Temporal misalignmet는 피할 수가 없음
Retrieval-Augmented Generation (RAG)
LLM을 학습시키지 않고 외부 데이터를 활용하는 방법론
외부 정보를 Prompt로 제공하는 방법
- Temporal alignment, Hallucination 개선
- 방법
- 알맞은 외부 정보를 제공하고 그 뒤에 질문을 넣는 방법
- 단, 알맞은 외부 정보를 제공하기 위한 방법이 필요함(Retrieval)
- 인터넷 검색
- Closed DB(메일함, 회사 내부 서류 등)
- 과거 생성 기록
- Retrieval 방법론: 질문과 벡터 서치를 통한 방법론 -> 고정된 크기의 벡터로 변환
- TF-IDF / BM25
- 단어 빈도를 활용하여 두 문장의 유사도를 측정
- Sentence-BERT
- BERT 기반 인코더를 학습하여 문장의 유사도를 학습
- Dense Passage Retrieval (DPR)
- 주어진 Query와 Passage의 유사도를 측정
- BERT 두 개로 질문과 문서의 CLS 토큰 벡터의 유사도를 측정하고 학습시키는 방법
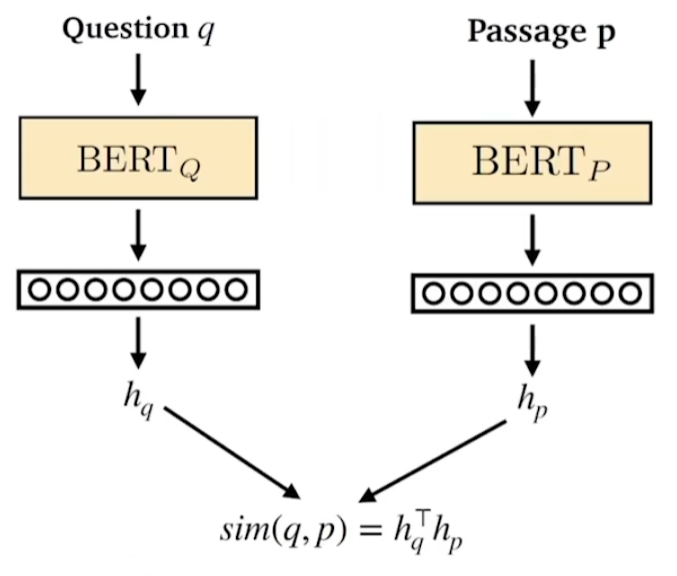
- TF-IDF / BM25
- 활용하고자 하는 문서들을 Vector DB에 저장
- FAISS, Pinecone 등 라이브러리 활용
- 질문 Context를 Query로 활용하여 벡터 검색을 진행함
- 벡터 검색 : 빠르게 활용할 땐, Approximate nearest neighbor 활용
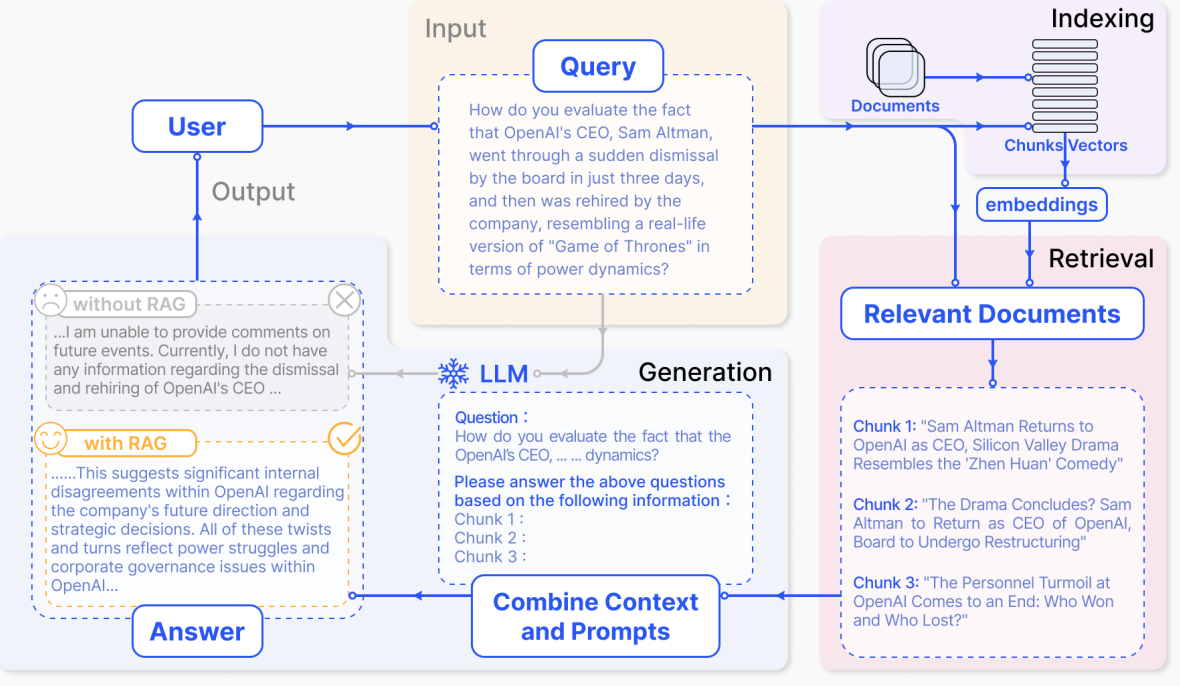
- (출처: Gao et al., "Retrieval-Augmented Generation for Large Language Models: A Survey", Arxiv, 2024)
- RAG 진행 과정
- 외부 문서들을 Chunk 단위로 Vector DB에 저장함
- User가 Query를 날리면 Vector DB에서 가장 유사한 청크를 찾음
- LLM의 입력으로 User의 Query와 추출된 Chunk를 넣어서 In-Context Learning 기반으로 결과를 생성함
- RAG의 한계
- RAG가 정확도를 향상시키지 못하는 경우
- Retrieval 프로세스가 좋지 못한 경우
- Retrieval에 활용하는 문서의 질이 좋지 못해서 노이즈가 되는 경우
- 이미 유명한 사실은 오히려 RAG를 쓰지 않았을 때가 더 성능이 높음
- Context에 정보를 넣어주더라도 정확히 따르지 않는 경우가 있음
- RAG가 정확도를 향상시키지 못하는 경우
Retrieval-Augmented Generation (RAG) 모델
- 모델의 개념으로 제시된 RAG
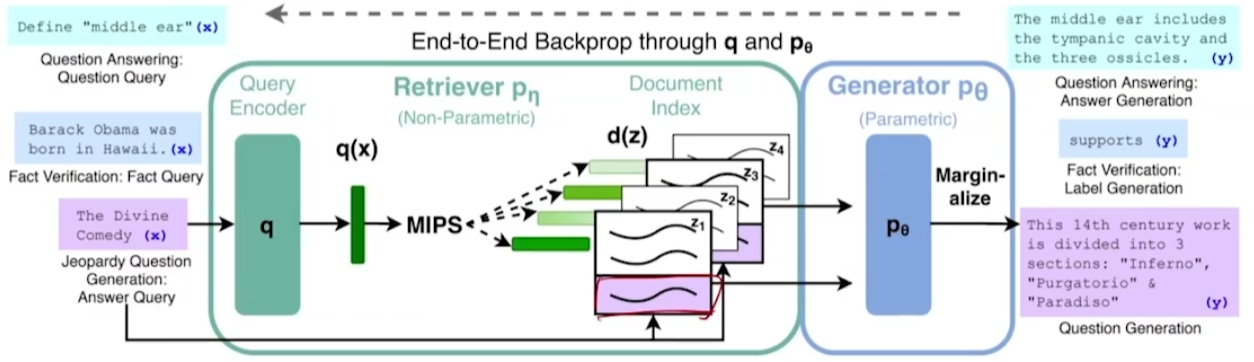
- User의 Query에 관한 여러 문서를 들고 온 뒤, 각 문서를 기반으로 계산된 토큰 확률 값을 Marginalize하여 하나의 텍스트를 생성
- 즉, 모든 문서에 대하여 P(y | D_1, Q)와 P(y | D_2, Q)... 확률을 구하고 이를 합하여 최종 텍스트를 만들어냄